Abstract

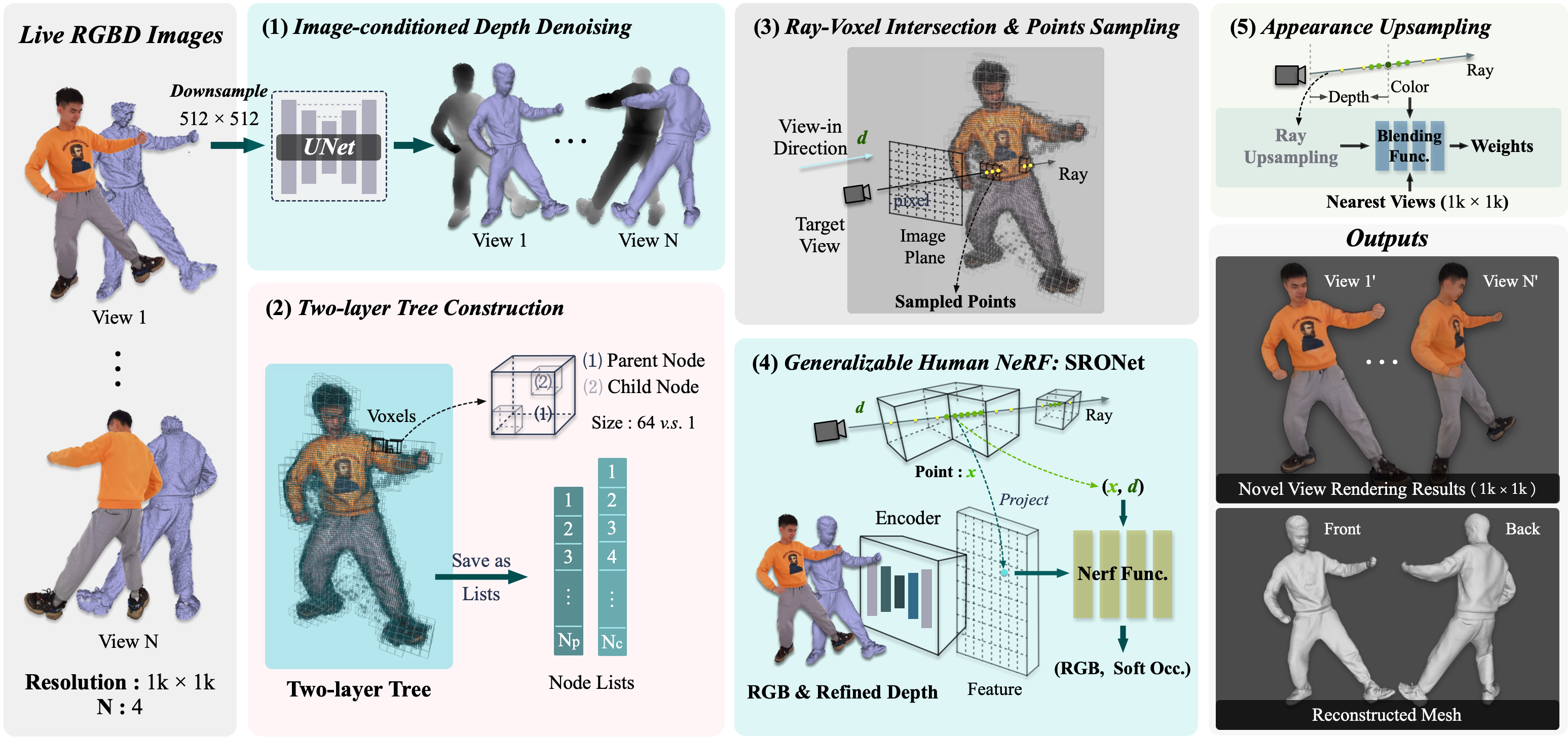
TL;DR: We propose SAILOR, a novel method for human free-view rendering and reconstruction from very sparse (e.g., 4) RGBD streams. It learns a hybrid representation of radiance and occupancy fields, which can handle unseen performers without additional fine-tuning.
Our free-view rendering results and bullet-time effects given input sparse RGBD streams on our real-captured dataset ( Unseen performers ).
Immersive user experiences in live VR/AR performances require a fast and accurate free-view rendering of the performers. Existing methods are mainly based on Pixel-aligned Implicit Functions (PIFu) or Neural Radiance Fields (NeRF). However, while PIFu-based methods usually fail to produce photorealistic view-dependent textures, NeRF-based methods typically lack local geometry accuracy and are computationally heavy (e.g., dense sampling of 3D points, additional fine-tuning, or pose estimation). In this work, we propose a novel generalizable method, named SAILOR, to create high-quality human free-view videos from very sparse RGBD live streams. To produce view-dependent textures while preserving locally accurate geometry, we integrate PIFu and NeRF such that they work synergistically by conditioning the PIFu on depth and then rendering view-dependent textures through NeRF. Specifically, we propose a novel network, named SRONet, for this hybrid representation. SRONet can handle unseen performers without fine-tuning. Besides, a neural blending-based ray interpolation approach, a tree-based voxel-denoising scheme, and a parallel computing pipeline are incorporated to reconstruct and render live free-view videos at 10 fps on average. To evaluate the rendering performance, we construct a real-captured RGBD benchmark from 40 performers. Experimental results show that SAILOR outperforms existing human reconstruction and performance capture methods.